AlphaGo
Is an AI developed by Google Deepmind that recently became the first machine to beat a top level human Go player.
AlphaToe
Is an attempt to apply the same techniques used in AlphaGo to Tic-Tac-Toe. Why? I hear you ask. Tic-tac-toe is a very simple game and can be solved using basic min-max.
Because it’s a good platform to experiment with some of the AlphaGo techniques which it turns out they work at this scale. Also the neural networks involved can also be trained on my laptop in under an hour as opposed too the weeks on an array of super computers that AlphaGo required.
The project is written in Python using TensorFlow, the Github is here https://github.com/DanielSlater/AlphaToe and contains code for each step that AlphaGo used in it’s learning. It also contains code for Connect 4 and this ability to build games of Tic-Tac-Toe on larger boards.
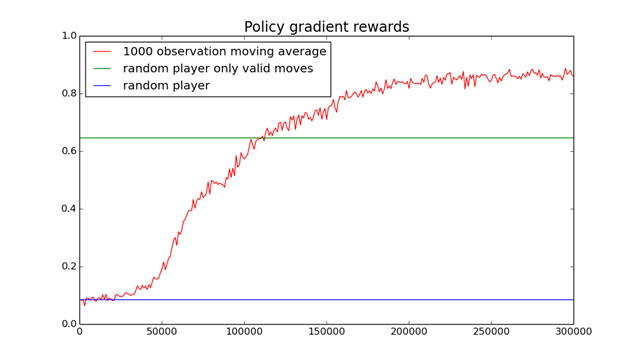
Here is a sneak peak at how it did in the 3×3 game. In this graph it is training as first player and gets too an 85% win rate against a random opponent after 300000 games.
Interesting project! It would be nice if you could add a very basic explanation on how to run it.
I tried to copy the “policy_gradient.py”-file to the root folder. But when ran it, it gave me this:
File “/home/hb9/projects/python/AlphaToe/network_helpers.py”, line 73, in save_network
pickle.dump(variable_values, f)
TypeError: write() argument must be str, not bytes
Hi hb9, glad your interested :). My current best explanation is given in the video of the talk. But I've now added more docs to each of the files which should help a bit more. Very surprised by your error, I find it runs fine. Can you send me the complete stack trace, as that error appears to be deeper in the pickle code? What version of python are you running? I've tested on python 2.7
Hey, python 3.5 still throws that error. I just tried it using 2.7 and now it's finally learning. Still it would be good to mention that one has to copy the script-file to the root folder and run it there (necessery for me at least). I would write some how-to-run-steps in the readme file.
You asked for the stack trace, here it is:
hb9@rocket:~/projects/python/AlphaToe$ python3 policy_gradient.py
loading pre-existing network
Traceback (most recent call last):
File “policy_gradient.py”, line 52, in
load_network(session, variables, NETWORK_FILE_PATH)
File “/home/hb9/projects/python/AlphaToe/network_helpers.py”, line 86, in load_network
variable_values = pickle.load(f)
TypeError: a bytes-like object is required, not 'str'
OK, I've worked out what was wrong and fixed it. In python 3+ pickle expected the file to be opened as a binary stream. New check in has this fixed and I've added a bit more explanation(though could still do with more). Hope this helps.
Hi, Daniel,
Thanks for sharing your interesting project. I ran policy_gradient.py first to generate the policy network by specifying NETWORK_FILE_PATH = 'current_network.p'. But I found the value of win_rate output is quit low. Is it because some of games end in a tie?
…
episode: 997000 win_rate: 0.106
episode: 998000 win_rate: 0.109
episode: 999000 win_rate: 0.113
When I continue to execute the 2nd step (python value_network.py), I got errors listed below. Do you know what causes that error? Thanks!
Instructions for updating:
Use `tf.global_variables_initializer` instead.
Traceback (most recent call last):
File “value_network.py”, line 66, in
load_network(session, reinforcement_variables, REINFORCEMENT_NETWORK_PATH)
File “/home/hd_songm/AlphaToe/common/network_helpers.py”, line 103, in load_network
Either delete the network file to train a new network from scratch or change the in memory network to match that dimensions of the one in the file””” % (file_path, ex))
ValueError: Tried to load network file current_network.p with different architecture from the in memory network.
Error was Dimension 0 in both shapes must be equal, but are 9 and 16 for 'Assign' (op: 'Assign') with input shapes: [9,100], [16,300].
Either delete the network file to train a new network from scratch or change the in memory network to match that dimensions of the one in the file
Hi Minghu, Sorry for the slow response, I've been quite busy.
Just had a chance to re-test this now, the big problem was I had been trying to get the network working with a 4×4 board and it working on that I had set the learning rate to 1-e6 which it seems is far too low to learn anything. Putting it back up to 1-e4 makes everything work smoothly again. I've done this in my last commit.
Also the other error you get is because the hidden nodes I had set up were different between the value network and policy network. I've now fixed this so they both run with 3 hidden layers with 100 nodes each and it seems to be working now.
My apologies, for leaving it in a bad state. Hope it works for you now 🙂