I’m going to be giving a talk/tutorial at PyDataLondon 2016 on Friday the 6th of may, if your in London that weekend I would recommend going, there are going to be lots of interesting talks, and if you do go please say hi.
My talk is going to be a hands on, on how to build a pong playing AI, using Q-learning, step by step. Unfortunately training the agents even for very simple games still takes ages and I really wanted to have something training while I do the talk, so I’ve built two little games that I hope should train a bit faster.
This a version of pong with some of visual noise stripped out, no on screen score, no lines around the board. Also when you start you can pass args for the screen width and height and the game play should scale with these. This means you can run it as an 80×80 size screen(or even 40×40) and save to having to do the downsizing of the image when processing.
This is an even kinder game than pong. There is only the players paddle and you get points just for hitting the other side of the screen. I’ve found that if you fiddle with the parameters you can start to see reasonable performance in the game with an hour of training(results may vary, massively). That said even after significant training the kinds of results I see are a some way off how well google deepmind report doing. Possibly they are using other tricks not reported in the paper, or just lots of hyper parameter tuning, or there are still more bugs in my implementation(entirely possible, if anyone finds any please submit).
I’ve also checked in some checkpoints of a trained half pong player, if anyone just wants to quickly see it running. Simply run this, from the examples directory.
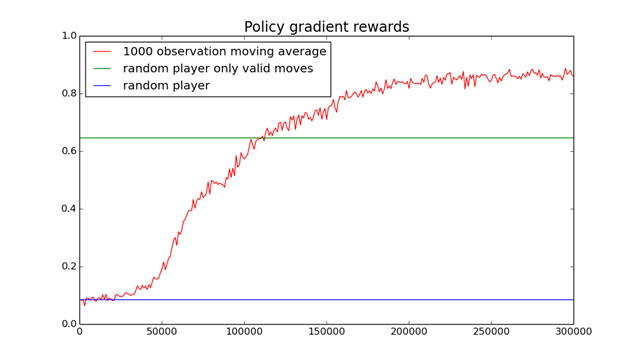
It performs significantly better than random, though still looks pretty bad compared to a human.
Distance from building our future robot overlords, still significant.