When training neural networks there are 2 things that combine to make life frustrating:
- Neural networks can take an insane amount of time of train.
- How well a network is able to learn can be hugely affected by the choice of hyper parameters(hyper parameters here refers mainly to the numbers of layer and numbers of nodes per layer, but can also include learning rate, activation functions, etc) and without training a network in full you can only guess at which choices are better.
My current research is around ways to try and get neural networks to adjust there size automatically, so that if there isn’t sufficient capacity in a network it will in some way determine this and resize itself. So far my success has been (very) limited, but while working on that I thought I would share this paper: Net2Net: Accelerating Learning via Knowledge Transfer which has a good, simple approach to resizing networks manually while keeping there activation unchanged.
I have posted a numpy implementation of it here on Github.
Being able to manually resize a trained network can give big savings on networks training time because when searching through hyper parameters options you can start off with a small partially trained network and see how adding extra hidden nodes or layers affects test results.
Net2Net comprises of 2 algorithms Net2WiderNet which adds nodes to a layer and Net2DeeperNet which adds a new layers. The code for Net2WiderNet in numpy looks like this:
https://gist.github.com/DanielSlater/edbecd61527aa4e833d947c4110c31b8.js
This creates the weights and biases for a layer 1 wider than the existing one. To increases the size by more nodes simply do this multiple times(note the finished library on github has the parameter new_layer_size to set exactly how big you want it). The new node is a clone of a random node from the same layer. The original node and it’s copy then have their outputs to the next layer halved so that the overall output from the network is unchanged.
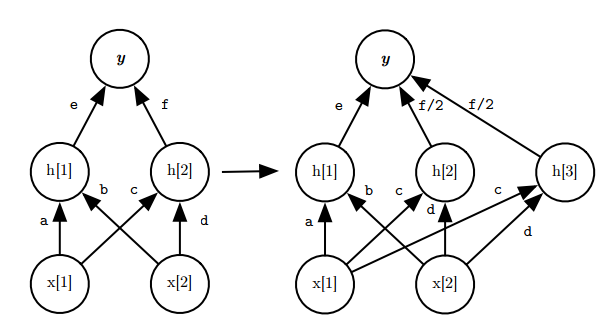 |
| How Net2WiderNet extends a layer with 2 hidden node layer to have 3 |
Unfortunately if 2 nodes in the same layer have exactly the same parameters then their activation will always be identical, which means their back propagated error will always be identical, they will update in the same way, their activation will still be the same, then you gained nothing by adding the new node… To stop this happening a small amount of noise is injected into the new node. This means as they train they have the potential to move further and further apart while training.
Net2DeeperNet is quite simple, it creates an identity layer, then adds a small amount of noise. This means that the network activation is only unchanged if the layer is a linear layer, because otherwise the activation functions non-linearity will alter the output. So bare in mind if you have an activation function on your new layer(and you almost certainly will) then the network output will be changed and will have worse performance until it has gone through some amount of training.
Here is the code:
BEGIN NET 2 DEEPER NET https://gist.github.com/DanielSlater/75df407b8f422e2b2c3d60bc65aeae14.js END NET 2 DEEPER NET
Usage in TensorFlow
This technique could be used in any neural network library/framework, but here is how you might use it in TensorFlow.
In this example we first train a minimal network with 100 hidden nodes in the first and second layers and train it for 75 epochs. Then we do a grid search of different numbers of hidden nodes for 50 epochs to see which lead to the best test accuracy.
https://gist.github.com/DanielSlater/96a4ccd17c2853026de8ad85856f1cc0.js
Here are the final results for the different numbers of hidden nodes:
| 1st layer | 2nd layer | Train accuracy | Test accuracy |
| 100 | 100 | 99.04% | 93.47% |
| 150 | 100 | 99.29% | 93.37% |
| 150 | 150 | 99.01% | 93.58% |
| 200 | 100 | 99.31% | 93.69% |
| 200 | 150 | 98.99% | 93.63% |
| 200 | 200 | 99.17% | 93.54% |


